
Si alguna vez te preguntaste cómo hace una inteligencia artificial para entender que “rey” y “reina” están relacionados, o que “fútbol” y “deporte” van de la mano, hay una palabra mágica detrás de todo eso: embeddings. Son el puente invisible entre el lenguaje humano, desordenado y ambiguo, y la matemática limpia y precisa de los algoritmos. Básicamente, son como convertir emociones, conceptos y sarcasmos en números… y que eso funcione.
En el fondo, el lenguaje natural es caos. Vos decís “me muero” y puede significar risa, sorpresa o estrés, todo según el contexto. Entonces, ¿cómo hace una máquina para no explotar tratando de entendernos? Ahí es donde entran los embeddings: una forma elegante de representar palabras, frases o incluso documentos como vectores en un espacio numérico. En otras palabras, transformar texto en puntos flotando en un universo donde la distancia sí importa.
La gracia es que estos puntos no están puestos al azar. Si entrenás un buen modelo de embeddings, las palabras con significados parecidos estarán cerca unas de otras. “Gato” y “perro” estarán más cerquita entre sí que “gato” y “cósmico”. Y eso le da a los modelos de NLP (procesamiento de lenguaje natural) una súper ventaja: pueden calcular similitudes, detectar contextos, clasificar intenciones, generar texto más coherente… todo gracias a este mapa numérico del idioma.
Ahora, pongamos las manos en el código. Si estás usando Python, tenés un arsenal de herramientas para trabajar con embeddings sin complicarte la vida. Una de las más populares es spaCy, que ya viene con modelos preentrenados que incluyen vectores semánticos. Basta con cargar un modelo, pasarle un texto, y te devuelve embeddings listos para usar.
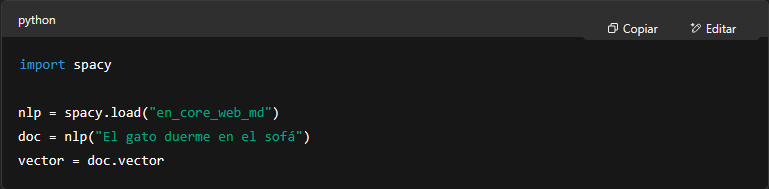
Ese .vector te da una representación numérica de toda la oración. Pero también podés trabajar palabra por palabra:

Ahora, si buscás más personalización o querés jugar con otros modelos, sentence-transformers es la estrella del momento. Basado en modelos tipo BERT, te permite generar embeddings de oraciones o párrafos completos con una calidad brutal. Ideal si estás haciendo búsquedas semánticas, clasificación de texto o recomendaciones inteligentes.
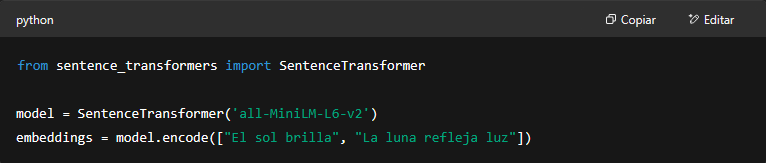
Y lo groso es que esos vectores los podés usar para comparar similitudes entre textos:
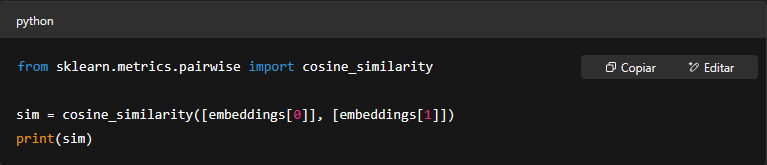
Esto es oro puro si estás armando un motor de búsqueda semántico, un sistema de preguntas y respuestas, o cualquier cosa donde necesites que la máquina “entienda” más allá de palabras exactas.
Lo que cambia el juego acá es que no estamos haciendo matching por coincidencias de texto literal, sino por cercanía en un espacio vectorial que captura significado. Esto abre puertas a un NLP mucho más intuitivo y adaptable. O sea, ahora podés hacer que tu app sugiera contenido similar, agrupe temas, filtre spam con mejor puntería o incluso escriba resúmenes que no parezcan hechos por un robot mal dormido.
Y sí, también podés entrenar tus propios embeddings. Con gensim y Word2Vec, por ejemplo, podés generar un modelo que entienda los matices de tu propio dataset, ya sea para analizar tweets, mails o reviews de tu e-commerce. Aunque eso ya es un nivel un poco más heavy, ideal si querés full control sobre lo que el modelo “aprende”.
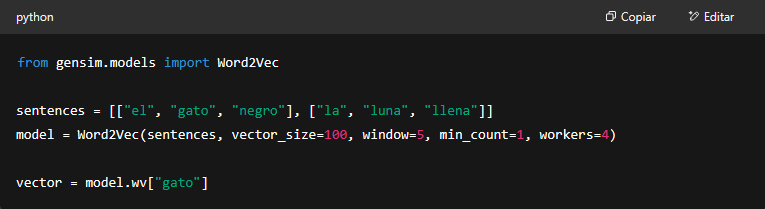
Y como todo en IA, no se trata de una bala de plata. Los embeddings son poderosos, pero también tienen limitaciones. Por ejemplo, no entienden ironías por sí solos, ni sarcasmos oscuros tipo “buenísimo que se rompió mi celular”, salvo que estén entrenados con suficiente contexto. Además, los embeddings clásicos como Word2Vec no distinguen entre significados de palabras según el contexto. Ahí los modelos tipo BERT y compañía los superan con creces.
Pero aún con todo eso, usar embeddings es uno de los trucos más simples y poderosos que podés aplicar en NLP sin meterte en el barro del deep learning más crudo. Es como tener un traductor entre la mente humana y los algoritmos: convierte palabras en coordenadas, ideas en geometría, emociones en álgebra… y aún así, todo sigue teniendo sentido.
En este juego donde las máquinas tratan de hablar humano, los embeddings son el idioma común. Son la clave para que un bot no solo repita cosas, sino que realmente entienda. Y en un mundo lleno de datos textuales, esa comprensión vale oro.
Así que sí, si quieres que tu IA hable con más inteligencia y menos copia-pega, es hora de que empieces a meter embeddings en tu stack como quien le mete sazón a una receta. Porque el texto puede ser un caos, pero con los vectores correctos… todo se alinea.